Option 2: Scan and Match Data
Use cached Account data and advanced filters to match or create Salesforce Accounts at scale.
Updated over a week ago
Scan and Match Data is a powerful method for connecting unmatched RestaurantologyLogs to existing Salesforce Accounts. Unlike real-time tools, this feature uses a cached version of your Account list to support advanced filtering and batch processing.
This tool is especially useful during initial implementation or for reviewing new unmatched records each month.
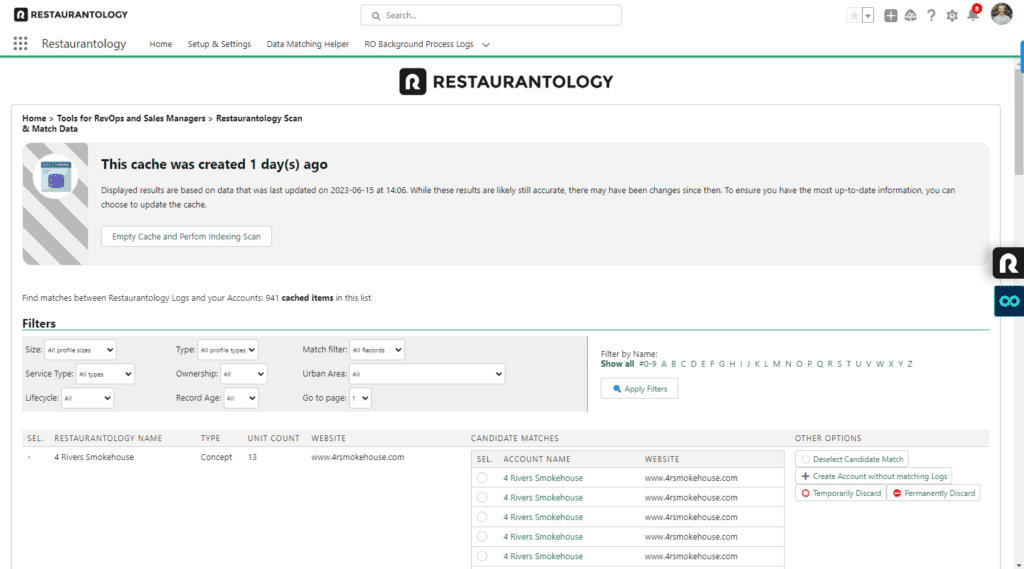
Accessing Scan and Match Data
Scan and Match Data is found in the Salesforce App Center:
- Click the 9-dot App Launcher in the upper-left of Salesforce.
- Type “Restaurantology” and open the Restaurantology App.
- From the App Center, select Scan and Match Data.
[!NOTE]
Users must have the proper profile and permissions to access this tool. If you’re unable to match or create Account records, contact your system administrator.
Creating and refreshing cache
Before using Scan and Match Data, you must create a cache of your current, unmapped Account records. Caching:
- Normalizes Account Names and Websites to improve match accuracy
- Enables advanced filters across large datasets
The initial cache process can take up to 5 hours, depending on the size of your Account list. Plan ahead and start your cache well before you intend to match data.
You can refresh your cache at any time, especially if:
- New RestaurantologyLogs have been added
- New Accounts were created (manually or via import)
- Previously discarded records need to be reconsidered
[!TIP]
Restaurantology and Salesforce data evolve constantly. Refresh your cache regularly to ensure relevance.
A progress bar tracks the indexing process.
Using advanced filters
Scan and Match Data includes all filters from the Data Matching Helper (Size, Record Type, Record Age, and Letter), plus additional advanced filters:
- Record Matches: Show only Logs with or without candidate matches
- Service Type: Filter by Full-Service or Limited-Service
- Ownership: Show only child or parent-linked records
- Urban Area: Filter by known urban area
- Lifecycle: Filter by inferred concept status
- Top Category: Filter by primary category (e.g., pizza, coffee)
Reviewing candidate matches
Like the Data Matching Helper, this tool surfaces candidate matches based on fuzzy logic comparing:
- Normalized Account Name vs. RestaurantologyLog Name
- Normalized Account Website vs. RestaurantologyLog Website
Some Logs may show multiple potential matches. Carefully review each before mapping.
[!TIP]
Mismatched records can always be remapped manually via the Account layout.
Creating new Accounts
If no strong match exists:
- Click Create Account next to the Log
- Or select multiple records and use the bulk Create Account button at the bottom
New Accounts are instantly mapped to the corresponding unmatched Logs.
Discarding records
You can discard Logs either temporarily (to remove them from view for now) or permanently (to exclude them from future matching workflows).
To learn more, see Discarding Records.
Pros and limitations
There are certain instances when Scan and Match data is both recommended and prioritized, however it’s important to know why certain features are not available in this particular widget.
Pros
- Uses higher-tolerance fuzzy matching for better accuracy
- Advanced filters help prioritize meaningful new Accounts
- Caching isolates a fixed dataset for focused matching
- Records can be temporarily or permanently excluded
Limitations
- Changes to Salesforce or Restaurantology data aren’t visible until the next cache refresh
- Still subject to Salesforce’s 2,000-row governor limit, though less frequently triggered than in real-time tools
- Caching can take up to 5 hours, depending on org size
Next, continue to Manual record matching →